Web Crawling (ou Rastreamento da Web)
Web Crawling (ou Rastreamento da Web) é o processo pelo qual um programa automatizado, conhecido como Web Crawler, Spider (aranha) ou Bot, navega na World Wide Web de forma metódica e sistemática.
Irei montar na prática um Crawling para poder mapear o domínio do grupo marquise: 'https://www.marquiseambiental.com.br
Utilizando Scrapy
Utilizarei a Biblioteca Scrapy, pela sua robustez e mecanismo, que facilita bastante o trabalho manual, já que a mesma faz inúmeros "trabalhos sujos" para a gente por baixo dos panos. A biblioteca Scrapy realiza uma grande parte do trabalho pesado para nós.
Ao utilizarmos o comando scrapy startproject nome_da_aranha, ela cria automaticamente toda a estrutura do projeto. Algo semelhante a isto:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ #project's Python module, you'll import your code from here
_init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
_init__.py
Peguei isso da documentação do Scrapy.
O Scrapy cuida das requisições feitas ao servidor (um problema que encontrei ao usar o BeautifulSoup, onde eu precisava aliá-lo à biblioteca urllib.request).
Em vez de implementar uma Fila padrão, você usa o comando yield para retornar um objeto Request.
Componentes do Scrapy
O Scrapy possui um componente chamado Scheduler (Agendador).
Ele é o responsável por receber todas as requisições que o spider gera, agendá-las e enviá-las para os Downloaders (componente do Scrapy responsável por acessar a internet e buscar as páginas) no momento apropriado.
Além disso, o Scrapy também possui um filtro de requisição duplicada embutido, garantindo que ele não visite a mesma URL várias vezes.
Definindo a Estrutura: Item e Grafos
Antes de explicar como a estrutura foi montada, há dois conceitos importantes que precisam ser mencionados: o conceito de Item, do Scrapy, e o conceito de Grafos.
Item
O Item é uma parte fundamental no Scrapy que funciona como um contêiner para armazenar os dados coletados durante a raspagem.
Além de armazenar, ele serve para estruturar e processar os dados coletados. O Scrapy suporta diferentes tipos de Itens (desde que sejam sustentados pela biblioteca itemadapter),
mas usaremos os Objetos Item, que funcionam de forma muito similar aos dicionários padrão do Python, porém com recursos (ou features) adicionais.
Grafos
Um modelo de Grafo é um conjunto de conexões, composto por Vértices (ou Nós) conectados por Arestas (linhas).
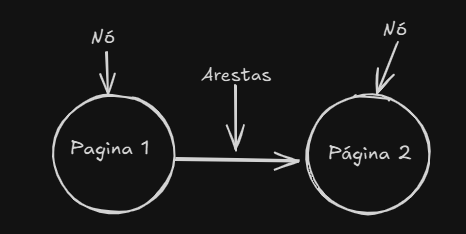
Um Nó pode ser conectado a vários outros Nós, que chamamos de vizinhos. Na Web, a estrutura de Grafos é amplamente usada para representar a Estrutura de Dados em Árvore, já que esta é a base da Web, como a Árvore DOM, por exemplo.
Como pretendemos mapear os sites que estão ligados sob o mesmo domínio, usaremos grafos para poder estruturar esses dados de forma mais eficaz.
Estrutura de Dados (items.py)
Para isso, editei o arquivo items.py (que foi criado automaticamente pelo Scrapy), onde defini a estrutura de dados que o spider irá avaliar a cada nova chamada. Isso é crucial, pois, a cada callback do spider, apenas os objetos reconhecidos como Itens são passados para a Pipeline.
Como iremos percorrer a Árvore Web inteira, partindo da raiz (o), criaremos nossos Nós (pagina_origem), que serão conectados pelas Arestas (links_destino).
class LinkGraphItem(Item):
pagina_origem = Field()
links_destino = Field()
E pronto! Preparamos a estrutura que será usada no nosso Web Crawling.
Programando o Bot
Na definição de nossa classe, que herdará de CrawlSpider, nomeamos o nosso spider/bot como: marquise_bot.
Além desse, definimos mais três atributos: o domínio que será seguido ao longo das requisições, chamado de allowed_domains; a URL de partida (start_urls),
que será "https://www.marquiseambiental.com.br", a "raiz" do domínio.
Observação: A Estrutura de Dados em Árvore é, sem dúvida, a predominante na Web. Ela vai desde a Árvore DOM até a forma como os sites se relacionam através das URLs. Embora o conceito predominante seja o de Árvore, aqui trataremos a estrutura como Grafos, o que será crucial para a modelagem dos dados mais adiante.
Por último, definimos nossas rules (regras), que estabelecem as condições que nosso spider irá seguir em suas requisições.
Definindo as Regras (Rules)
rules = (
Rule (LinkExtractor(allow=r'marquiseambiental\.com\.br'),
callback='parse_item',
follow True),
)
Utilizamos a classe Rule do Scrapy, na qual instanciamos outro objeto: o LinkExtractor.
Dentro dele, inserimos uma regex básica para garantir que o bot seguirá somente links internos do domínio.
No callback, indicamos a função que o bot irá chamar a cada nova requisição, que é a função parse_item. Para que o bot siga os links encontrados de forma recursiva, definimos o parâmetro follow como True.
Função parse_item
Em seguida, partiremos para a função parse_item:
def parse_item(self, response):
No início da função, inseri um print apenas para avisar que uma nova requisição começou. Primeiramente, capturamos todos os links da página. Usando o objeto response (que é o objeto da requisição), empregamos o seletor CSS (a::attr(href)) para buscar todos os atributos href da tag <a>.
Também criamos um Conjunto (conjunto_links) para coletar nossos links. A razão para usar a estrutura Conjunto é simples: ela não permite a repetição de elementos, garantindo que não armazenaremos o mesmo link várias vezes.
print("DEBUG: Processando a página: " + response.url)
links_encontrados response.css(" a::attr(href)").getall()
conjunto_links = set()
Depois, criamos uma condição de checagem para verificar se o bot encontrou links:
if not links_encontrados:
print("DEBUG: Nenhum link encontrado!")
print("DEBUG: conteudo da resposta:\n" + response.text[:500])
Em seguida, criamos um laço for para iterar sobre os links encontrados na página:
for link in links_encontrados:
link_absoluto response.urljoin(link)
if self.allowed_domains [0] in link_absoluto:
conjunto_links.add(link)
Antes de qualquer coisa, utilizamos response.urljoin(link) para converter o link em um formato absoluto, evitando erros, já que diversos links internos são relativos (exemplo: /contato).
Lembra do parâmetro allow, no LinkExtractor? Poderíamos ter deixado o trabalho para ele, mas preferimos fazer uma última checagem para ter certeza de que não estamos adicionando nenhum link que não pertença ao domínio.
Finalmente, conectamos a estrutura de dados com o nosso Bot. Instanciamos a classe que criamos (LinkGraphItem). A cada requisição, o bot pega a URL atual e a armazena no atributo/nó chamado pagina_origem.
Em seguida, todos os links guardados no nosso conjunto são armazenados no atributo links_destino, que representa nossas arestas.
item = LinkGraphItem()
item['pagina_origem'] = response.url
item['links_destino'] = list(conjunto_links)
yield item
Para finalizar, utilizamos o yield para retornar o nosso objeto Item para uma nova requisição, repetindo o processo recursivamente.
Extração dos Dados
Conforme mencionado, os Objetos Item do Scrapy se assemelham a dicionários padrão do Python, mas com recursos extras.
O Scrapy possui um Item Exporter que pode exportar os dados coletados pelo Objeto Item para vários tipos de arquivos, desde CSV até JSON.
Como o nosso modelo se baseia em Grafos e a melhor maneira de representá-lo em código é por meio de dicionários, optamos por exportar os dados para JSON, já que a estrutura de ambos é bastante similar.
Faço isso digitando o comando: scrapy crawl marquise_bot -o grafo_links.json no terminal. E ele cria um arquivo json na raiz do projeto e grava os dados coletados lá.
)
pagina_origem e links_destino).Como dá para ver, é bastante dados bruto, quase não dá para ler.
Lembrando que essa imagem é só uma parte do arquivo KKKKK!!.
Análise de Dados
Agora, iremos fazer o trabalho de uma analista de dados. [cite_start]Como eu tive que fazer inúmeras verificações, não tem um código "definitivo". Eu alterei o código váaarias vezes para perceber os padrões que o código seguia.
import json
with open('grafo_links.json', 'r', encoding='utf-8') as f:
lista_de_paginas = json.load(f)
grafo = {}
for item in lista_de_paginas:
pagina = item['pagina_origem']
links = item['links_destino']
grafo[pagina] = links
print(f"Grafo concluido! Total de {len(grafo)} nós mapeadas")
raiz = 'https://www.marquiseambiental.com.br'
for link in grafo[raiz]:
if ('/noticias' or '/noticias_') in link:
display(link)
No entanto, para a análise, utilizarei somente os dados obtidos no rastreamento dos links presentes na página principal do domínio.
Ao analisar os diferentes links, percebi que havia dois padrões de caminho que se referiam a Notícias:
/noticias: Levava à página que listava as diferentes notícias (o feed ou arquivo de notícias)./noticias_: Era usado como o caminho base para os artigos (páginas individuais de notícia).
Não é possível determinar o motivo dessa dualidade sem acesso à estrutura de desenvolvimento do site (já que não podemos "ler pensamentos" ou adivinhar a lógica por trás da implementação).
A execução do código mostrou:
)
Executando o código que mostrei, ele mostra todos os links que estão ligados aos dois caminhos "noticias".
Há muitos caminhos, simplesmente muuuitos. Tive que rodar muito código e alterar para extrair padrão e poder mapear.
Mapeação
Depois, fui abrir o Excalidraw para desenhar uma parte da arquitetura do site e cheguei nessa conclusão:
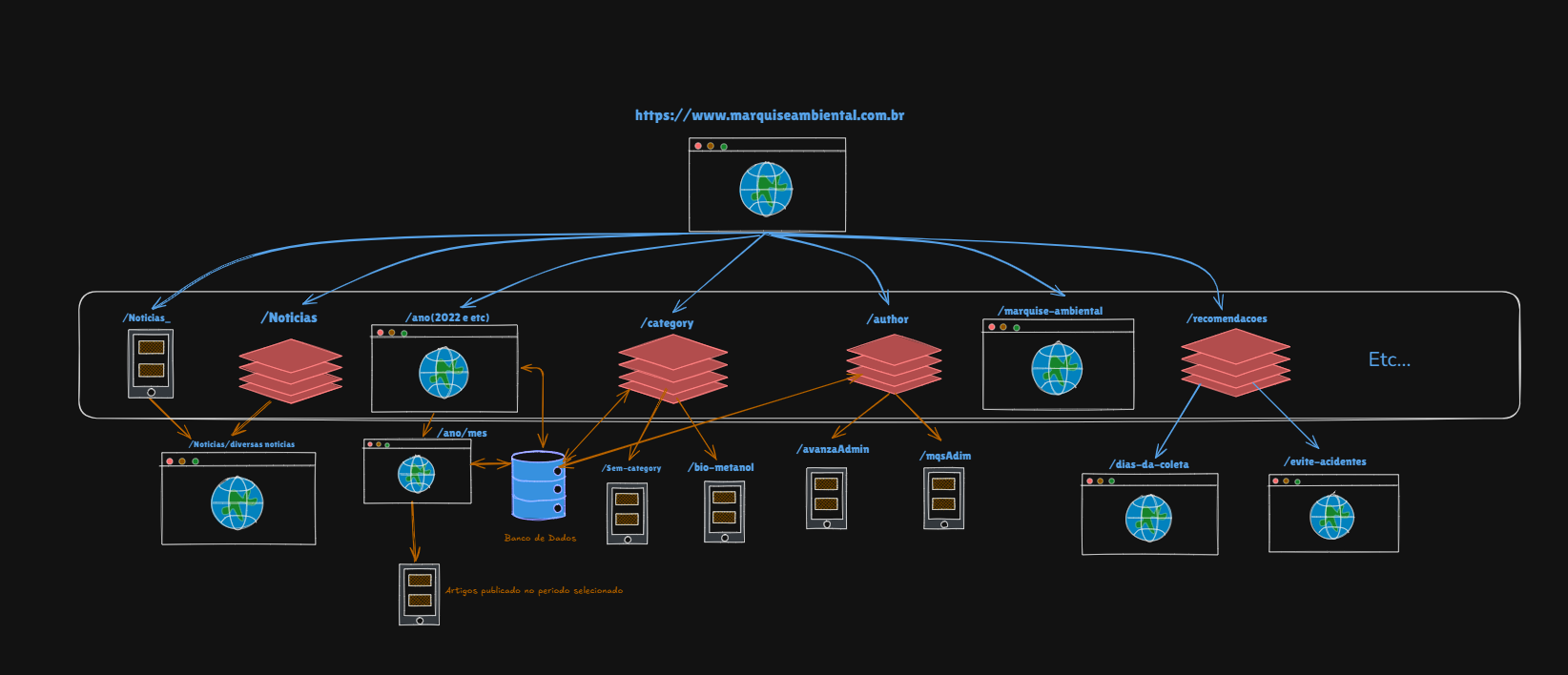
Mencionei que há muitos outros caminhos que não seguiam um padrão claro ou que apareciam apenas uma única vez.
Por isso, mapeei somente aqueles que demonstravam ter vários outros sites (ou páginas) ligados a eles.
Muitos desses caminhos, na verdade, não levavam a uma página final, servindo apenas como camadas de navegação ou diretórios.
Isso fica evidente no caso do caminho /noticias_ que servia simplesmente para conectar a alguns artigos e nada mais, enquanto o caminho /noticias era o que, de fato, levava à página que listava os diferentes artigos.